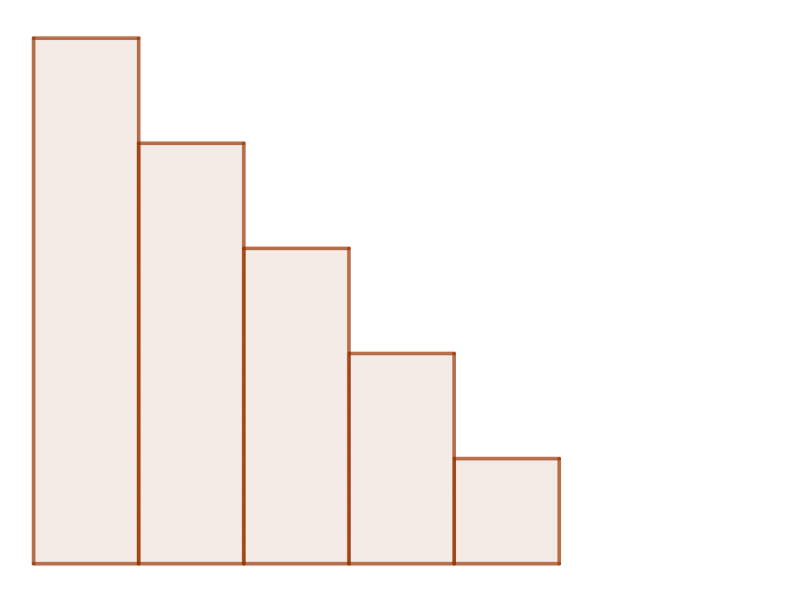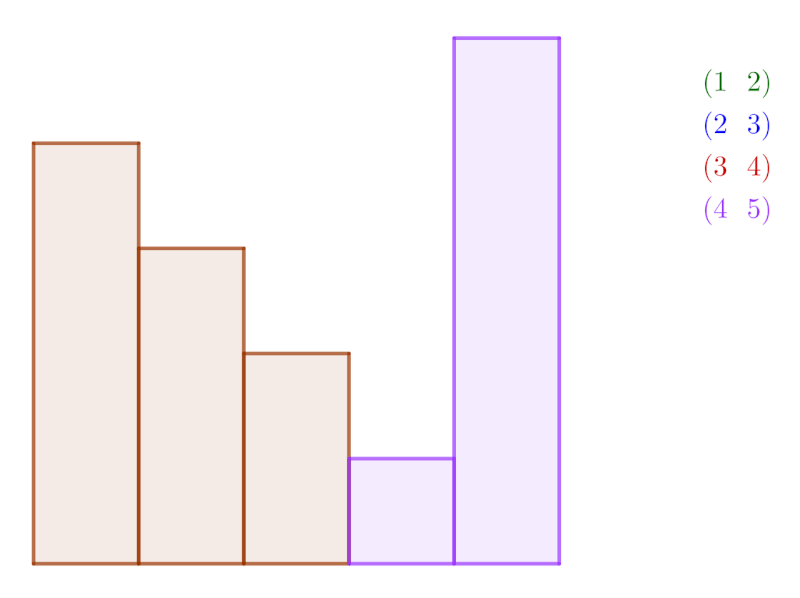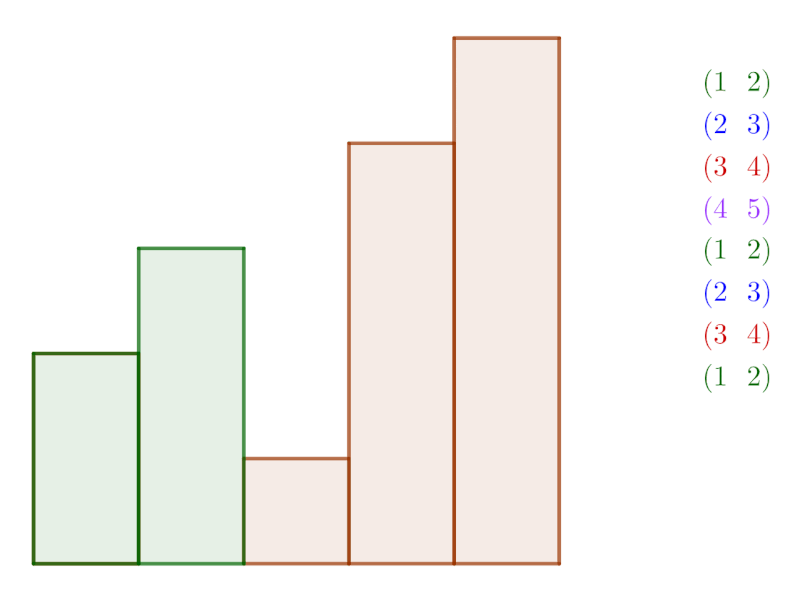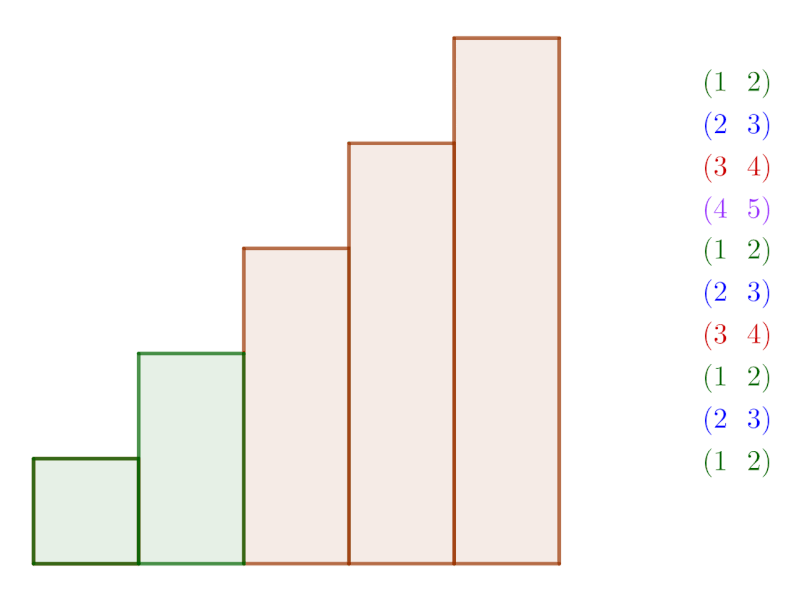Some basic, interesting connections between graph theory and permutation groups.
Published
January 18, 2022
Modified
July 4, 2025
In the time since my last post discussing graphs, I have been spurred on to continue playing with them, with a slight focus on abstract algebra. This post will primarily focus on some fundamental concepts before launching into some constructions which will make the journey down this road more manageable. However, I will still assume you are already familiar with what both a group and a graph are.
The Symmetric Group
Some of the most important finite groups are the symmetric groups of degree n (S_n). They are the groups formed by permutations of lists containing n items. There is a group element for each permutation, so the order of the group is the same as the number of permutations, n!.
On lists versus sets
The typical definition of the symmetric group uses sets, which are fundamentally unordered. This is potentially confusing, since it can appear as though an object after applying a permutation is the same object as before.
For example, let p be the permutation swapping “1” and “3”. Then,
After applying p, the set is unchanged, since all of the elements are the same. On the other hand, the lists differ in the first element and cannot be equal.
Sets are still useful as a container. For example, the elements of a group are unordered. To keep vocabulary simple, I will do my best to refer to objects in a group as “group elements” and the objects in a list as “items”.
There are many ways to denote elements of the symmetric group. I will take the liberty of explaining some common notations, each of which are useful in different ways. More information about them can be found elsewhereonline as well as any adequate group theory text.
Naive List Notation
Arguably the simplest way to do things is to denote the permutation by the result of applying it to a canonical list. Take the element of S_3 which can be described as the action “assign the first item to the second index, the second to the third, and the third to the first”. Our canonical list in this case is [1, 2, 3], matching the degree of the group. This results in [3, 1, 2], since “1” is in now in position two, and similarly for the other items.
Unfortunately, this choice is too result-oriented. This choice makes it difficult to compose group elements in a meaningful way, since all of the information about the permutation is in the position of items in the list, rather than the items of the list themselves. For example, under the same rule, [c, b, a] is mapped to [a, c, b].
True List Notations (Two- and One-line Notation)
Instead, let’s go back to the definition of the element. All we have to do is list out every index on one line, then the destination of every index on the next. This is known as two-line notation.
For simplicity, the first row is kept as a list whose items match their indices.
This notation makes it easier to identify the inverse of a group element. All we have to do is sort the columns of the permutation by the second row, then swap the two rows.
Note that the second row is now the same as the result from the naive notation.
Since the first row will be the same in all cases, we can omit it, which results in one-line notation. The nth item in the list now describes the position in which n can be found after the permutation.
Double brackets are used to distinguish this as a permutation and not an ordinary list.
These notations make it straightforward to encode symmetric group elements on a computer. After all, we only have to read the items of a list by the indices in another. Here’s a compact definition in Haskell:
-- convenient wrapper type for belownewtypePermutation=P { unP :: [Int] }apply ::Permutation-> [a] -> [a]apply =flip (\xs ->map ( -- for each item of the permutation, map it to... (xs !!) -- the nth item of the first list. (+(-1)) -- (indexed starting with 1) ) . unP) -- (after undoing the type wrapping)-- written in a non-point free formapply' (P xs) ys =map ( \n -> ys !! (n-1) ) xsprint$P [2,3,1] `apply` [1,2,3]
[2,3,1]
Note that this means P [2,3,1] is actually equivalent to [\![2, 3, 1]\!]^{-1}, since we don’t get [3, 1, 2].
While these notations are fairly explicit and easy to describe to a computer, it’s easy to misinterpret an element as its inverse. There is also some redundancy: [\![2, 1]\!] and [\![2, 1, 3]\!] both describe a group element which swaps the first two items of a list. On one hand, the S_n each belongs to is explicit, but on the other, every element of a smaller symmetric group also belongs to a larger one. The verbosity of these notations also makes composing group elements difficult1.
Cycle Notation
Cycle notation addresses all of these issues, but gets rid of the transparency with respect to lists. Let’s try phrasing the element we’ve been describing differently.
assign the first item to the second index, the second to the third, and the third to the first
We start at index 1 and follow it to index 2, and from there follow it to index 3. Continuing from index 3, we return to index 1, and from then we’d loop forever. This describes a cycle, denoted as (1 ~ 2 ~ 3).
Cycle notation is much more delicate than list notation, since the notation is nonunique:
Naturally, the elements of a cycle may be cycled to produce an equivalent one.
(1 ~ 2 ~ 3) = (3 ~ 1 ~ 2) = (2 ~ 3 ~ 1)
Cycles which have no common elements (i.e., are disjoint) commute, since they act on separate parts of the list.
(1 ~ 2 ~ 3)(4 ~ 5) = (4 ~ 5)(1 ~ 2 ~ 3)
Cycle Algebra
The true benefit of cycles is that they are easy to manipulate algebraically. For some reason, Wikipedia does not elaborate on the composition rules for cycles, and the text which I read as an introduction to group theory simply listed it as an exercise. While playing around with them and deriving these rules oneself is a good idea, I will list the most important here:
Cycles can be inverted by reversing their order.
(1 ~ 2 ~ 3)^{-1} = (3 ~ 2 ~ 1) = (1 ~ 3 ~ 2)
Cycles may be composed if the last element in the first is the first index on the right. Inversely, cycles may also be decomposed by partitioning on an index and duplicating.
(1 ~ 2 ~ 3) = (1 ~ 2)(2 ~ 3)
If an index in a cycle is repeated twice, it may be omitted from the cycle.
Which is exactly what we expected with our naive notation.
Generators, Permutation Groups, and Sorting
If we have a group G, then we can select a set of elements \langle g_1, g_2, g_3, ... \rangle as generators. If we form all possible products – not only the pairwise ones g_1 g_2, but also g_1 g_2 g_3 and all powers of any g_n – then the products form a subgroup of G. Naturally, such a set is called a generating set.
Symmetric groups are of primary interest because of their subgroups, also known as permutation groups. Cayley’s theorem, a fundamental result of group theory, states that all finite groups are isomorphic to one of these subgroups. This means that we can encode effectively any group using elements of the symmetric group.
For example, consider the generating set \langle (1 ~ 2) \rangle, which contains a single element that swaps the first two items of a list. Its square is the identity, meaning that its inverse is itself. The identity and (1 ~ 2) are the only two elements of the generated group, which is isomorphic to C_2, the cyclic group of order 2. Similarly, the 3-cycle in the generating set \langle (1 ~ 2 ~ 3) \rangle generates C_3, the cyclic group of order 3.
However, the generating set \langle (1 ~ 2), (1 ~ 2 ~ 3)\rangle, which contains both of these permutations, generates the entirety of S_3. In fact, every symmetric group can be generated by two elements: a permutation which cycles all elements once, and the permutation which swaps the first two elements.
The proof linked to above, that every symmetric group can be generated by two elements, uses the (somewhat obvious) result that one can produce any permutation of a list by picking two items, swapping them, and repeating until the list is in the desired order.
This is reminiscent of how sorting algorithms are able to sort a list by only comparing and swapping items. As mentioned earlier when finding inverses using in two-line notation, sorting is almost the inverse of permuting. However, not all 2-cycles are necessary to generate the whole symmetric group.
Bubble Sort
Consider bubble sort. In this algorithm, we swap two items when the latter is less than the former, looping over the list until it is sorted. Until the list is sorted, the algorithm finds all such adjacent inversions. In the worst case, it will swap every pair of adjacent items, some possibly multiple times. This corresponds to the generating set \langle (1 ~ 2), (2 ~ 3), (3 ~ 4), (4 ~ 5), …, (n-1 ~\ ~ n) \rangle.
Bubble sort ordering a reverse-sorted list
Selection Sort
Another method, selection sort, searches through the list for the smallest item and swaps it to the beginning. If this is the final item of the list, this results in the permutation (1 ~ n). Supposing that process is continued with the second item and we also want it to swap with the final item, then the next swap corresponds to (2 ~ n). Continuing until the last item, this gives the generating set \langle (1 ~ n), (2 ~ n), (3 ~ n), (4 ~ n), …, (n-1 ~\ ~ n) \rangle.
Selection sort ordering a particular list, using only swaps with the final item
This behavior for selection sort is uncommon, and this animation omits the selection of a swap candidate. The animation below shows a more destructive selection sort, in which the candidate least item is placed at the end of the list (position 5). Once the algorithm hits the end of the list, the candidate is swapped to the least unsorted position, and the algorithm continues on the rest of the list.
“Destructive” selection sort. The actual list being sorted consists of the initial four items, with the final item as temporary storage.
Swap Diagrams
Given a set of 2-cycles, it would be nice to know at a glance if the entire group is generated. In cycle notation, a 2-cycle is an unordered pair of natural numbers which swap items of an n-list. Similarly, the edges of an undirected graph on n vertices (labelled from 1 to n) may be interpreted as an unordered pair of the vertices it connects.
If we treat the two objects as the same, then we can convert between graphs and sets of 2-cycles. Going from the latter to the former, we start on an empty graph on n vertices (labelled from 1 to n). Then, we connect two vertices with an edge when the set includes the permutation swapping the indices labelled by the vertices.
Returning to the generating sets we identified with sorting algorithms, we identify with each a graph family.
The star graphs (\bigstar_n, as S_n means the symmetric group), one vertex connected to all others.
Every 2-cycle in S_n
The complete graphs (K_n), which connect every vertex to every other vertex.
This interpretation of these objects doesn’t have proper name, but I think the name “swap diagram” fits. They allow us to answer at least one question about the generating set from a graph theory perspective.
Connected Graphs
A graph is connected if a path exists between all pairs of vertices. The simplest possible path is simply a single edge, which we already know to be an available 2-cycle.
The next simplest case is a path consisting of two edges. Some cycle algebra shows that we can produce a third cycle which corresponds to an edge connecting the two distant vertices.
\begin{align*}
&(m ~ n) (n ~ o) (m ~ n) \\
&= (m ~ n ~ o) (m ~ n) \\
&= (n ~ o ~ m) (m ~ n) \\
&= (n ~ o ~ m ~ n) \\
&= (o ~ m) = (m ~ o)
\end{align*}
Note that this is just the conjugation of (n ~ o) by (m ~ n)
In other words, if we have have two adjacent edges, the new edge corresponds to a product of elements from the generating set. Graph theory has a name for this operation: when we produce all new edges by linking vertices that were separated by a distance of 2, the result is called the square of that graph. In fact, higher graph powers will reflect connections induced by more conjugations of adjacent edges.
As you might be able to guess, this implies that (1 ~ 4) = (3 ~ 4)(2 ~ 3)(1 ~ 2)(2 ~ 3)(3 ~ 4). Also, \bigstar_n^2 \cong K_n.
If our graph is connected, then repeating this operation will tend toward a complete graph. Complete graphs contain every possible edge, and so correspond to all possible 2-cycles, which trivially generate the symmetric group. Conversely, if a graph has n vertices, then for it to be connected, it must have at least n - 1 edges. Thus, a generating set of 2-cycles must have at least n - 1 items to generate the symmetric group.
Picking a different vertex labelling will correspond to a different generating set. For example, in the image of P_4 above, if the edge connecting vertices 1 and 2 is replaced with an edge connecting 1 and 4, then the resulting graph is still P_4, even though it describes a different generating set. We can ignore these extra cases entirely – either way, the graph power argument shows that a connected graph corresponds to a set generating the whole symmetric group.
Disconnected Graphs
A disconnected graph is the disjoint union of connected graphs. Under graph powers, we know that each connected graph tends toward a complete graph, meaning a disconnected graph as a whole tends toward a disjoint union of complete graphs, or cluster graph. But what groups do cluster graphs correspond to?
The simplest case to consider is what happens when the graph is P_2 \oplus P_2. If there is an edge connecting vertices 1 and 2 and an edge connecting vertices 3 and 4, it corresponds to the generating set \langle (1 ~ 2), (3 ~ 4) \rangle. This is a pair of disjoint cycles, and the group they generate is
One way to look at this is by considering paths on each component: we can either cross an edge on the first component (corresponding to (1 ~ 2)), the second component (corresponding to (3 ~ 4)), or both at the same time. This independence means that one group’s structure is duplicated over the other’s, or more succinctly, gives the direct product. In general, if we denote γ as the map which “runs” the swap diagram and produces the group, then
\gamma( A \oplus B ) = S_{|A|} \times S_{|B|},
~ A, B \text{ connected}
where |A| is the number of vertices in A.
γ has the interesting property of mapping a sum-like object onto a product-like object. If we express a disconnected graph U as the disjoint union of its connected components V_i, then
\begin{gather*}
U = \bigsqcup_i V_i
\\
\gamma( U ) = \gamma \left( \bigsqcup_i V_i \right) = \prod_i S_{|V_i|}
\end{gather*}
This describes γ for every simple graph. It also shows that we’re rather limited in the kinds of groups which can be expressed by a swap diagram.
Closing
This concludes the dry introduction to some investigations of mine into symmetric groups. While I could have omitted the sections about permutation notation and generators, I wanted to be thorough and tie it to concepts which were useful to my understanding. The notion of a graph encoding a generating set in particular will be fairly important going forward.
Originally, this post was half of a single, sprawling, meandering article. I hope I’ve improved the organization by keeping the digression about sorting algorithms to this initial article. The next post will cover some interesting structures which fill Euclidean space and incredibly large graphs.
Sorting and graph diagrams made with GeoGebra.
Footnotes
Composition is relatively easy to describe in two-line notation. Recall that we reordered columns when finding an inverse. We can do so to match rows of two elements, then compose a new element by looking at the first and last rows. For example, with group inverses:
\begin{pmatrix}
1 & 2 & 3 \\
2 & 3 & 1
\end{pmatrix}
\begin{pmatrix}
1 & 2 & 3 \\
2 & 3 & 1
\end{pmatrix}^{-1}
= \begin{matrix}
\begin{pmatrix}
1 & 2 & 3 \\
\cancel{2} & \cancel{3} & \cancel{1}
\end{pmatrix}
\\
\begin{pmatrix}
\cancel{2} & \cancel{3} & \cancel{1} \\
1 & 2 & 3
\end{pmatrix}
\end{matrix}
= \begin{pmatrix}
1 & 2 & 3 \\
1 & 2 & 3
\end{pmatrix}
↩︎